Statisticians refer to this as "uncorrelated" data. Every part of a cipher should be uncorrelated: no bit of the plaintext should correlate with any bit of the ciphertext, and no two bits of the ciphertext should be correlated with each other--any correlations indicate more random differences could be added, masking the ciphertext, and any correlations could be used as a fingerprint of the cipher to indicate what cipher is being used.
However, any instance of perfectly random data will have deviations from perfect randomness. In fact, if I run a billion tests, and I get *exactly* half a billion 0's and half a billion 1's, this makes me instantly suspicious the output could be repeating itself. There is one exception: if you scan the entire plaintext space, which is perfectly balanced between 0 and 1, the entire ciphertext space is typically also perfectly balanced, because typical ciphers are permutations (if a cipher has n bits of input, and n bits of output, and it's reversible, it must be a permutation). I "discovered" this fact after my laptop spent half an hour scanning the entire 32-bit input space for RC5!
In theory, if the outputs from a cipher are independent (uncorrelated) and identically distributed (half 1, half 0), then the central limit theorem states the average approximates a normal distribution with variance:
standard deviation of average = standard deviation of bits / sqrt(n bits)
As you increase the number of bits tested, n, the average bit balance should get closer and closer to 0.5. Deviations of the average that are a large multiple of the standard deviation indicate the data is probably not independent or not identically distributed, either of which indicates a serious flaw in the cipher.
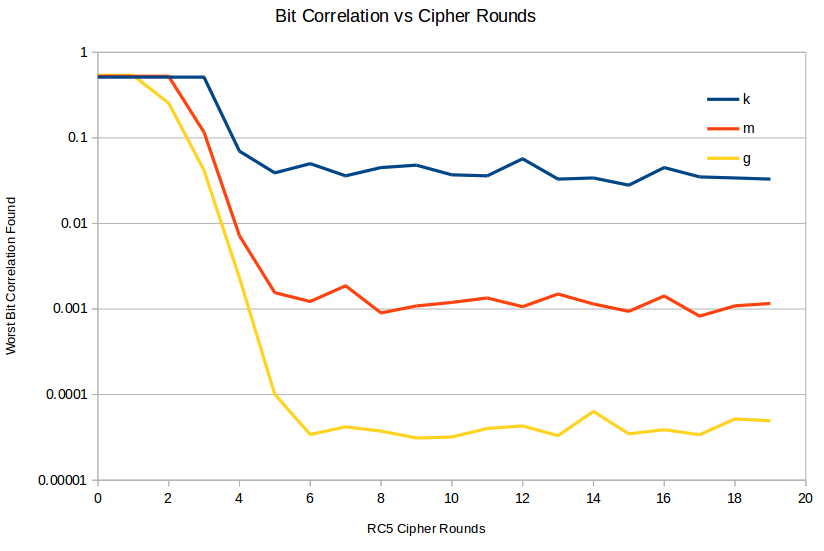
Here's a chart of the deviations from 0.5 measured for various RC5 round counts for various sample sizes: k for 1000 samples, m for 1000000 samples, and g for 1000000000 samples. Clearly, below 4 rounds, the RC5 output has serious deviations from randomness. Above about 6 rounds, the cipher seems OK, at least as measured by this test.