In Proceedings of the High Performance Computing Symposium - HPC '99,
pages 59-64.
Data Intensive Volume Visualization on the Tera MTA and Cray
T3E
Allan Snavely, Greg Johnson and Jon Genetti
San Diego Supercomputer Center at University of
California San Diego
9500 Gilman Drive, La Jolla, California 92093-0505
Abstract
Raycasting is a DVR (Direct Volume Rendering) technique. DVR is a class of
techniques for graphically visualizing 3D data. The data can be from any
source as long is it is representable by discrete sample values at each
point in a three dimensional grid. Common sources of such data include CT
(Computed Tomography), MRI (Magnetic Resonance Imaging), and ultrasound
scans. The data can come from simulation or direct measurement of physical
phenomena. Direct volume rendering is by nature highly memory intensive.
For example, a high resolution representation of a human female, The
Visible Female dataset, is 36 gigabytes. A raycasting algorithm must
typically visit each byte of this data to produce an image. A further
challenge is to optimize DVR algorithms for data locality. Desktop
workstations do not currently have the memory or compute power to visualize
such large datasets quickly. Yet quick response to user requests for view
changes are important to allow interactive exploration. We describe a
software system, the MPIRE (Massively Parallel Interactive Rendering
Environment), developed at SDSC (San Diego Supercomputer Center), which
brings the power of a supercomputer to the desktop via the Web and allows
interactive explorations of massive datasets. Currently MPIRE runs on two
very different supercomputers; the Cray T3E and the MTA (Tera Multithreaded
Architecture). We compare and contrast the architectures of these machines
and characterize the porting effort and performance of MPIRE on each.
Introduction
Complex physical phenomena are often best investigated by visual inspection.
There is no substitute for seeing for ones-self the contours of the problem
under scrutiny; whether it be the ocean floor, the human brain, or the
reactive surface of a molecule. Today, computers aid in the work of science
by turning masses of numbers into pictures on the screen. If view changes
can be completed quickly, the scientist can interact with the data in real
time, virtually skimming the ocean floor, slicing through a diseased organ
or inspecting the shape of a protein docking site. However, when the dataset
to be visualized is large, the practical challenge of turning data bytes into
image pixels can be immense. Specifically, changing the view point and
forming a new image of a multi-gigabyte dataset in under 10 seconds is beyond
the current capabilities of most desktop system. Clearly, powerful
supercomputers such as the Cray T3E and the MTA (Tera Multithread
Architecture) [1, 5, 6] provide an alternative. But most researchers do not
have a supercomputer sitting next to them. What they do have (in many cases)
is a PC or workstation running Netscape with Java. Using SDSC's (San Diego
Supercomputer Center's) MPIRE (Massively Parallel Interactive Rendering
Environment) software [3], this is enough to deliver the power of the
supercomputer to the desktop.
The MTA and the T3E embody very distinct approaches to supercomputing.
The machines are different architecturally and this leads to different
programming styles. The T3E reflects current mainstream thinking on how
to build a supercomputer from commodity components. The MTA is an
experimental machine which is constructed from custom components. At SDSC
we are tasked with evaluating the Tera MTA approach. While we have studied
the MTA's performance on a number of benchmarks and applications [2], this
paper presents our first evaluation of a full user application on the MTA.
Below we give a quick overview of volume rendering in general and an
intuitive explanation of the steps involved in raycasting [4]. We then
describe the software architecture of MPIRE and go on to describe the
porting process to the two supercomputers. Porting involves mapping
an algorithm (an abstract recipe for performing a calculation) to an
architecture (a physical realization of a machine.) One must have an
understanding of both the architecture and the algorithm to obtain a high
performance port. Lastly, since performance is the ultimate measure
of supercomputers, we give performance measurements on both machines.
Volume Rendering
Volume rendering takes a (regular or irregular) 3D grid of datapoints and
constructs a 2D regular grid of pixels called a raster. A pixel is a tuple
of color and opacity, the resulting raster grid can be displayed by a
computer screen as an image. Since volume rendering algorithms have to
visit each datapoint to construct an accurate image, and since each pixel
of the raster has to be colored in, it's easy to see that the runtime of
the algorithm is:
O( n 3 +
p 2 )
where n is the dimension of the volume and p the dimension of
the image (volume and image assumed symmetrical for simplicity of analysis).
Raycasting is one of a class of algorithms that employ no intermediate
polygon representation of the data but build up the values of the raster
by direct reference to the dataset. This class of algorithms is termed DVR
(Direct Volume Rendering). DVR algorithms are the choice for scientific
visualization applications when the density of interesting features is high
and the accuracy of representation is crucial.
Raycasting
The raycasting process is easily understood by analogy.
Imagine an eye looking through a window at a 3D object. If the window
were replaced by a perfect picture of the outside view, then the eye
would be fooled into thinking that the picture was the actual object
(see Figure 1).
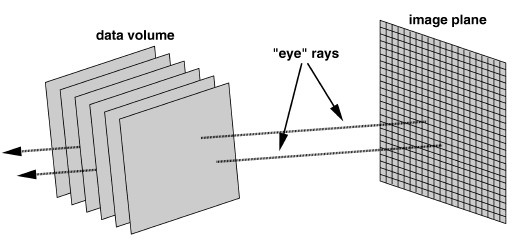 |
Figure 1: Raycasting works by casting
virtual rays through the data volume, one per pixel in the image
plane. The volume is sampled at unit increments along the ray.
These samples are combined to determine the color and opacity of
the corresponding pixel. |
Raycasting accomplishes this trick by breaking the window pane up into
small squares (pixels) and tracking the path of a ray originating at the
eye through each pixel and out to the object. Based on the substances in
the object encountered by the ray, the algorithm assigns a color and
opacity to the pixel. Note that the object is represented in the computer
by a 3D array of datapoints. So, to come a step a closer to describing the
actual algorithm , raycasting fills in an image plane by stepping through
the volume, once for each pixel of the raster, in an order prescribed by
the viewpoint. For each change in the orientation of the eye relative to
the scene, a new calculation must be performed.
MPIRE
Researchers at the San Diego Supercomputer Center have developed a
distributed direct volume rendering system which utilizes advances in high
performance computing architecture, web programming, and information
delivery. Called MPIRE, this system can render multi-gigabyte volume
datasets at near-interactive rates and deliver the results to any desktop
computer equipped with a web browser.
MPIRE consists of three components. One of these components is a set of
software engines for performing the rendering calculations. The engines
are based on highly parallel implementations of the splatting (called
Splatter) and ray casting (Caster) direct volume rendering algorithms.
MPIRE also includes software for performing resource allocation and engine
execution on a supercomputer. Finally, MPIRE includes graphical interface
panels for interactively controlling the rendering process on the remote
supercomputer. Java applet and Application Visualization System (AVS)
implementations of the MPIRE interface include buttons, sliders, and other
controls for providing truly interactive exploration of the target
dataset.
To the user, MPIRE is much like any other menu driven program. After
loading a web page containing the MPIRE Java applet, the user configures
the desired rendering parameters, target system, and number of processors.
A MPIRE engine is then automatically started on the target system over the
specified number of processors (if available), the data loaded, and an
image created and sent back to the Java applet. The image is automatically
updated by the engine as the user modifies the camera position, lighting,
coloration, or any other rendering parameter.
This architecture provides accurate, dynamic rendering of multi-gigabyte
volume data at rates unattainable by any other means. Researchers using
MPIRE at SDSC have achieved rendering rates of 350 million voxels (volume
elements) per second -- 9 seconds per image for a 9 gigabyte dataset of the
Visible Male [7], using 256 CPUs of the Cray T3E there (see Figure 2).
Raycasting with MPIRE on the T3E
T3E Architecture
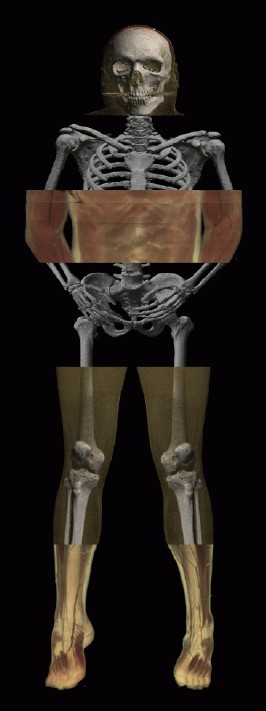 |
Figure 2: A mosaic of images created from
the Visible Male dataset emphasizing different tissue types.
|
| |
The T3E is assembled from a large number of commercial workstation class
processors. Our model uses the DEC Alpha EV5 processor which runs at 300
MHz and is theoretically capable of 600 MFLOPS per processor. These
processors (in our configuration 272 of them) are tied together in a 3D
toroidal mesh by a high bandwidth, low latency network. Programming a
machine like the T3E presents a special challenge. Each processor has
its own local memory. The programmer has to break a large problem into
distinct pieces which can each run on a separate processor and then combine
the results from each processor at the end of the calculation. The
combining step, and intermediate calculations requiring remote data, must
be explicitly programmed. The process of decomposing a problem into
subproblems so that it can be solved in this fashion is termed
parallelization. In general it may not be obvious how to
parallelize a problem. However raycasting is rather easy to parallelize.
Porting to the T3E
An intuitive first pass at a parallel implementation of raycasting on a the
T3E relies on the observation that each ray can be cast independently. One
could imagine a processor assigned to each ray and all processors casting
their rays at the same time. In reality there are many more pixels (and
thus rays) than processors, so each processor must be tasked with casting a
bundle of rays. Further, each processor has limited local memory (128
megabytes in our T3E configuration). It is not possible for each processor
to have a private copy of the 36 gigabyte Visible Female [7] for example.
But dividing the data across processors in this case suggests that each
processor must access the volume data in memory on every other processor for
each ray it casts. Doing so is inefficient given that remote memory
references take longer than references to local memory. A different
approach is to break each ray into sections. A processor can compute the
section of the ray corresponding to the data it has. When all of the rays
have been cast, each processor is left with a rendered image of just the
partition of the data volume stored in its local memory. The corresponding
pixels in the images on each processor must then be composited together in
the order that they would have been accumulated had the rays not been broken
into sections. Thus remote memory references are still required, but since
the number of pixels in an image is generally much smaller than the number
of samples in a volume, the amount of data that must be exchanged between
processors is minimized.
At SC '98 in Orlando, we set a world record for sustained performance on
a DVR type calculation over a multi-gigabyte dataset. Using MPIRE on 260
processors of the T3E at SDSC we rendered the Visible Female dataset at full
resolution (36 gigabytes) and displayed the results in near-interactive time
(~12s per frame) on an SGI workstation on the exhibit floor. This
demonstration was our entry in the HPC Challenge competition; the judges
awarded us `Most Revealing`.
Raycasting with MPIRE on the MTA
MTA Architecture
The MTA is a radical new supercomputer designed around the concept of
multithreading. A thread is a series of instructions. It can be thought of
as a piece of a program. The instructions to cast one ray can be a thread
for example. A multithreaded machine such as the MTA keeps the contexts of
several threads in registers close to the processor. This means that when
one thread encounters a long latency instruction, such as a memory reference
(which may take many processor cycles to satisfy), another thread can step in
and use the processor. This strategy keeps the processors of a multithreaded
machine at a higher rate of utilization than is normally possible for single
threaded processors. The MTA takes this concept to the extreme, keeping 128
contexts in banks of registers called streams on each processor. The
MTA can have up to 256 processors by design. Each processor runs at 260 MHz
and is theoretically capable of 780 MFLOPS. However, to date only a 4
processor machine has been built. SDSC has this machine, serial #001 of the
Tera MTA! The MTA is designed to perform well on highly parallel, memory
intensive problems such as raycasting.
Like the T3E, memory in the MTA is physically distributed and globally
addressable. Unlike the T3E, the MTA has no local memory. All memory is
remote from all processors. Our MTA configuration has 4 gigabytes of
memory. Instead of each processor having its own memory and exchanging
data via messages, all processors can write directly to all memory. One
might wonder why other machines do not adapt this scheme since it is easier
for the user to program. The answer lies in the complexity of making a
single global memory from distributed memory modules. Also, a logically
flat memory which is not local to any individual processor takes longer to
access for all processors. The cleverness of the Tera MTA architecture is
that it is designed to tolerate this long memory latency by finding other
work for each processor to do while waiting.
Porting to the MTA
Porting MPIRE to the MTA is simplicity itself. The raycasting loop looks
like this:
/* go through the raster a pixel at a time */
#pragma tera assert parallel
for ( i=0 ; i < xsize ; i++ ) {
#pragma tera assert parallel
for ( j=0 ; j < ysize ; j++ ) {
index = i + j * xsize;
image[index] = SampleRay(R, v);
}
}
|
SampleRay is a function that steps through the shaded volume (v) compositing
color and opacity for each argument (R) of type ray. To convince the Tera
compiler to multithread this double loop, it was simply necessary to attach
the pragmas. No further source code modifications were required. The Tera
compiler can often find parallel loops and multithread them without a pragma
directive. However, in this case, the compiler was unsure of the side
effects of SampleRay and was unwilling to automatically parallelize without a
hint from the programmer. It is the simplicity of a flat memory programming
model (no hierarchy in the form of cache or local memory) that makes it
possible to program the MTA in this very straightforward style. Also, the
simple programming model makes the compiler's job easier. There is no
equivalent compiler for the T3E. One cannot take a program written for a
single processor workstation and compile it to get a multiprocessor message
passing program suitable for the T3E. The programmer must supply the effort
to decompose the problem into pieces.
Further, recall that the T3E implementation of raycasting requires a pixel
composition step due to the distribution of the volume data across the
local memory of all processors. This step is unnecessary on the MTA. Each
of the processors works on its own part of the image which resides in
shared memory addressable by all processors.
The parallel executable resulting from the compile can be run on one or
more MTA processors. Since each call to SampleRay corresponds to a thread
and since there is hardware for 128 threads per processor, it only makes
sense to use more that one processor if there are more than 128 calls to
SampleRay. Because a typical image is 400 x 400 = 160K pixels (rays), there
is plenty of parallel work in most render jobs to justify the use of
multiple MTA processors.
Performance Comparison
For the purposes of comparing the two machines we chose the head region of
the Visible Male downsampled to 30 megabytes. Table 1 shows the time spent
in the SampleRay loop by the MTA on this problem for 1, 2, 3 and 4
processors. Also given is parallel efficiency, the ratio of speedup on
multiple processors to ideal speedup. This metric gives an indication of
how efficient the machine is in devoting extra hardware to the same size
problem.
| Processors |
Raycasting |
Parallel Efficiency |
| 1 |
3.67s |
|
| 2 |
1.89s |
97% |
| 3 |
1.32s |
93% |
| 4 |
0.97s |
95% |
| 8 |
n/a |
n/a |
| 16 |
n/a |
n/a |
| |
Table 1: Performance of the SampleRay (raycasting) loop on
the Tera MTA for a 256 ³ sample data volume and 400 x
400 pixel image plane. |
|
|
| Processors |
Raycasting |
Parallel Efficiency |
| 1 |
16.31s |
|
| 2 |
8.56s |
95% |
| 3 |
6.82s |
80% |
| 4 |
5.45s |
75% |
| 8 |
3.19s |
64% |
| 16 |
2.08s |
49% |
| |
Table 2: Performance of the SampleRay (raycasting) loop on
the Cray T3E for a 256 ³ sample data volume and 400 x
400 pixel image plane. |
|
Table 2 shows the time spent in the SampleRay loop and in compositing by the
T3E. Recall that the MTA does not need to composite pixels. Comparing the
two tables indicates that the MTA is outperforming the T3E by more than 4 to
1 per single processor. Since the clock speeds are roughly comparable, this
may at first seem surprising. The reason lies in the memory access patterns
of raycasting. A 3D volume partition in the local memory of a T3E node is
actually stored as a linear array of addresses. When a ray is cast through
the volume, the physical stride between array elements accessed depends on
the incident angle of the ray. While some angles may luckily result
in unit strides which correspond to the contiguous addresses of a cache line,
most will not. Most of the time you will incur the penalty of a cache miss
for every memory reference on the T3E. This is not a problem that can be
solved by changing the order of data storage. The most efficient data
storage order depends on the viewpoint. But the user may choose any
viewpoint.
The MTA pays the same penalty per memory reference as the T3E since it has no
cache. However, when one thread goes to memory, another thread steps in and
issues an instruction. The processor-memory bandwidth of the MTA is 8 bytes
per cycle. The T3E's is only 2 bytes per cycle when it misses cache.
Raycasting is a massively parallel problem with poor data locality. The
critical path for such a problem is processor-memory bandwidth. The ratio of
single processor performance between these two architectures is proportional
to their memory bandwidth. Further, the MTA processors are kept at a higher
rate of utilization due to their ability to context switch between threads
when one is waiting for memory.
The rapidly degenerating parallel efficiency of the T3E on this problem is an
artifact of problem size. To allow comparison between the two machines we
chose a size of problem suitable for 1-4 processors on either. The overhead
of starting up the rendering loop on each processor would be better amortized
for larger problems on the T3E. The MTA is less sensitive to problem size
because its parallel model is very fine grained. Each processor does its
fair share of thousands of rays. The T3E splits the volume into smaller
pieces for more processors giving each processor less data. If this is
carried too far, the overhead of loop startup and message passing becomes a
large fraction of total runtime.
Note, that while the MTA is the likely winner for small and medium sized
problems, the current configuration has 4 gigabytes of main memory vs. an
aggregate total of more than 36 gigabytes on the T3E. This means that the
T3E remains our machine of choice for truly large renders, at least until a
larger MTA configuration becomes available.
Future Work
Delivery of a 4 CPU MTA at SDSC came just prior to the deadline for
submission to this conference. We hope, by the time of our presentation,
to give the results of multi-gigabyte renders on both supercomputers.
Conclusion
MPIRE brings the power of supercomputers to the desktop, allowing
researchers to visually explore large datasets interactively. The Tera MTA
and Cray T3E are both excellent rendering engines. The Tera MTA has unique
architectural features that give it some advantages on problems such as
raycasting which, while parallel, exhibit poor data locality.
Acknowledgments
This work was supported in part by NSF award ASC-9613855 and DARPA contract
DABT63-97-C-0028. The development of MPIRE was sponsored by CRI through the
University Research and Development Grant Program.
References
| 1. |
|
Boisseau, Jay, Larry Carter, Allan Snavely, David Callahan, John Feo, Simon
Kahan and Zhijun Wu. "CRAY T90 vs. Tera MTA: The Old Champ Faces a New
Challenger", Cray User's Group Conference, June 1998, pp. TBD.
|
| 2. |
|
Carter, Larry, John Feo and Allan Snavely. "Performance and Programming
Experience on the Tera MTA", SIAM, April 1999, pp. TBD.
|
| 3. |
|
Johnson, Greg and Jon Genetti. "MPIRE: Massively Parallel Interactive
Rendering Environment", http://mpire.sdsc.edu. |
| 4. |
|
Levoy, Marc. "Display of Surfaces From Volume Data", IEEE Computer
Graphics and Applications, 1988, 8(3), pp. 29-37. |
| 5. |
|
Snavely, Allan, Larry Carter, Jay Boisseau, Amit Majumdar, Kang Su Gatlin,
Nick Mitchell, John Feo and Brian Koblenz. "Multi-processor Performance
on the Tera MTA", SC 98, November 1998, pp. TBD. |
| 6. |
|
Snavely, Allan, Nick Mitchell, Larry Carter, Jeanne Ferrante and Dean Tullsen.
"Explorations in Symbiosis on two Multithreaded Architectures", M-TEAC,
January 1999, pp. TBD. |
| 7. |
|
"The Visible Human Project",
http://www.nlm.nih.gov/research/visible/visible_human.html.
|