Searching a Computer
Computer
Security I Lecture, Dr. Lawlor
Legal Issues: Search vs Seizure
The typical way to collect digital evidence from a storage device is
to "image" the device: take a complete byte-for-byte copy of
everything on the device. But this "seize everything" approach
is difficult to square with old legal principles that predate cheap
perfect copies:
The right of the people to be secure in their persons,
houses, papers, and effects, against unreasonable searches and
seizures, shall not be violated, and no Warrants shall issue, but
upon probable cause, supported by Oath or affirmation, and
particularly describing the place to be searched, and the persons
or things to be seized.
United States Constitution, 4th Amendment
For something so important, a standard of "unreasonable searches and
seizures" seems disappointingly qualitative, but this is what we
have to work with.
Imagine though that I image your phone. If I search the image
in detail, I now have access to:
- The names and numbers for everyone you've ever communicated
with on that phone
- Every web page you've ever visited, and every web search
you've ever done, including the really embarrassing ones
- Saved logins to your web accounts for financial records,
educational records, and social media
- Photographs of you, your friends, your family, your pets, and
your leisure activities
- Your location history, which reveals your home address,
employer, friends addresses, vacation destinations, and where
you sleep
Traditionally, the police have the right to search the pockets of a
person being arrested, but for a phone, this degree of intrusion
doesn't seem reasonable.
Because with digital data it's so easy to seize and search
everything, the US
Supreme Court's unanimous 2014 Riley vs California
decision (Volokh analysis) drew a legal
distinction between search (looking at the data for evidence
of a particular crime) and seizure (taking or imaging the
device).
This means for evidence you collect to be useful in court, you may
now need a search warrant to analyze a device currently held by the
police, which should describing what evidence you're looking for,
and why it's relevant. Having some clue exactly what you're
looking for is probably a good idea in general.
High Level Tools
There are a number of professional-grade tools for performing
forensic analyses. They tend to be commercial software with a
copy protection dongle, and only run on Windows.
- FTK
/ Forensic Toolkit: currently $5K. Backed by a
database (currently PostgreSQL), and supports distributed
indexing. There is a related mobile device forensics tool
MPE+.
- EnCase:
currently over $3K. Stores hard disks in the proprietary
Expert Witness format. Has a Decryption Suite add-on for
encrypted drives.
- IEF
/ Internet Evidence Finder: about $2K. Can
reconstruct chat history, performs geographic searches.
- X-Ways
Forensics: starting at $1K. An evolution of the
winhex hex editor.
The only free and cross platform tools I've found are:
Filesystem Details
Any filesystem is just a big binary data structure sitting on your
disk. One common filesystem, used in USB keychain drives,
floppy disks, and old hard disks, is the "File
Allocation Table" filesystem.
The first thing on disk is the FAT "boot sector", which tells you
how many entires are actually in the FAT. Then comes the FAT
itself (read the Wikipedia article, it's good!). Then comes
the blocks of data in the normal user files sitting on the
disk. Because the boot sector, FAT, and user data blocks are
all a known size, the OS can directly seek (the disk) to a
particular location to read a particular file.
It uses an interesting trick to keep track of the blocks in a
file. The file's blocks are basically kept in a big linked
list, with each block in the file pointing to the next block until
you hit the last block, which is marked with a "-1" link.
Partitions
So you've got a disk. The disk stores bytes. You can in
theory access the raw disk (and some database systems do this for
speed!), but it's way more common to build several layers of storage
on top of the raw disk bytes:
- Disks are divided into "partitions", which are just pieces of
the disk used for different things. You can make one disk
appear as your C, D, and E drives by splitting it into three
partitions. You can install Windows and Linux on the same
disk using two partitions.
- Partitions are formatted with a "filesystem", like FAT, NTFS,
or Linux ext3.
- Filesystems contain many files, like "README.txt".
- Some file formats contain sub-pieces, like media container
formats like avi or mp4, or complex formats like office
documents (.docx and .pptx are just zip files with an xml
index).
There are currently two major partition schemes in use on PCs:
- The old Master Boot Record (MBR) stores 4 primary partitions
right in the boot sector, and extended partitions in subsequent
sectors. Since the format began in the DOS era, there are
a variety of weird limitations and vendor-dependent workarounds
and special cases, like the current 2TB partition size limit (=
2^32 sectors of size 512 bytes each).
- The new GUID
Partition Table (GPT) partition format was introduced by
Intel with their new UEFI
firmware. It supports more partitions (124 of them),
bigger partitions, and UEFI booting.
Example: Windows Disk Manager
To get to the Windows Disk Manager, first right-click on "My
Computer" and hit "Manage", then select "Disk Manager" near the
bottom of the left-hand side list. This shows you all your
disks, and importantly all your partitions:
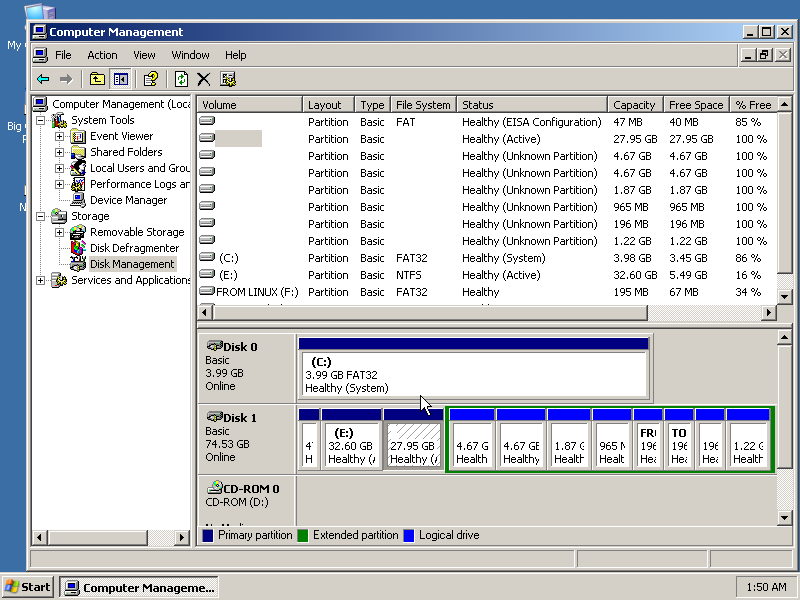
The original design of the IBM PC's "boot sector / MBR" (the first
512 bytes of the disk) left room for only four "primary"
partitions. Since people running multiple operating
systems often want more than this, you can also make an "extended"
partition (in green above) that counts as a primary partition, but
contains other smaller "logical drive" partitions inside of
it. You can also leave unpartitioned space on your disk,
which can later be used to create new partitions.
If your partition table gets horribly screwed up, you may still be
able to recover your partitions and all their data using a tool like
TestDisk.
Example: Linux fdisk
The same disk viewed in Windows above can be examined in Linux like
so:
root@dellawlor:/home/olawlor/class/cs321/lecture/fs_fat # fdisk /dev/hda
Command (m for help): p
Disk /dev/hda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 1 6 48163+ de Dell Utility
/dev/hda2 * 7 4262 34186320 7 HPFS/NTFS
/dev/hda3 * 4263 7910 29302560 83 Linux
/dev/hda4 7911 9729 14611117+ 5 Extended
/dev/hda5 7911 8519 4891761 83 Linux
/dev/hda6 8520 9128 4891761 83 Linux
/dev/hda7 9129 9372 1959898+ 83 Linux
/dev/hda8 9373 9495 987966 82 Linux swap
/dev/hda9 9496 9520 200781 b W95 FAT32
/dev/hda10 9521 9545 200781 b W95 FAT32
/dev/hda11 9546 9570 200781 83 Linux
/dev/hda12 9571 9729 1277136 83 Linux
Command (m for help): q
Again, I've got a bunch of partitions. /dev/hda2 is my Windows
partition. /dev/hda3 is my main Linux partition. /dev/hda4
is my extended partition, which contains hda5 through hda12.
Reading the List of Files in a Directory
So a directory (a folder) is just a list of files and other
directories. This list is stored as a set of bytes, usually
with one fixed-size structure per file plus a variable-length name
list. So a directory is just a bunch of bytes, and you can store
those bytes (a directory's list
of files) inside another file! That is, a directory is just a
file that's marked "this file's bytes represent other files and
directories". Curious, no?
Reading the files in a directory is just exactly like reading a file,
although the names have been changed to protect you from the details of
the filesystem.
In UNIX systems: Linux, Mac OS X, etc.
Start with opendir, which takes a directory name and returns a "DIR *".
List each file with readdir, which takes a "DIR *" and returns a
"struct dirent *", which has a "d_name" field telling you the name of
the file.
Finish up with closedir, which frees the "DIR *".
#include <dirent.h> /* UNIX directory-list header */
#include <time.h> /* for "timespec", used in bits/stat.h (& whined about by icpc) */
#include <sys/stat.h> /* to tell if an item is a file or directory */
void unix_list(const char *dirName)
{
DIR *d=opendir(dirName);
if (d==0) return;
struct dirent *de;
while (NULL!=(de=readdir(d))) {
const char *name=de->d_name;
hit_file(dirName,name);
}
closedir(d);
}
In Windows
Start with FindFirstFile, which takes a directory plus filename
pattern, and returns a HANDLE and a WIN32_FIND_DATA. The
WIN32_FIND_DATA struct contains the name of the first matching file in
"cFileName", and the file's attributes (permissions) in
"dwFileAttributes".
A call to FindNextFile will find the next matching file.
Call FindClose when done.
#include <windows.h>
void win_list(const char *dirName)
{
char dirNamePat[1024];
sprintf(dirNamePat,"%s\\*",dirName); /* dirName, with trailing slash-star */
WIN32_FIND_DATA f;
HANDLE h=FindFirstFile(dirNamePat,&f);
if (h==INVALID_HANDLE_VALUE) return;
do {
const char *name=f.cFileName;
if (strcmp(name,".")==0 || strcmp(name,"..")==0)
continue; /* Bogus self links */
// printf("---dirName: %s, file: %s\n",dirNamePat,name);
if (f.dwFileAttributes&FILE_ATTRIBUTE_DIRECTORY)
hit_directory(dirName,name);
else
hit_file(dirName,name);
} while (FindNextFile(h,&f));
FindClose(h);
}
At the Raw Block Level