mov rax,3 retOn my 4GHz Skylake machine, this takes 1.2ns. But so does this:
mov rax,3 xor rax,7 add rax,2 ret
The extra operations come "for free" because we're still waiting for the function call to finish.
You can get sub-nanosecond timing resolution by the usual trick of repeating the operation. Since this loop runs 1000 times, the output time is actually picoseconds (10-12 seconds) per iteration instead of nanoseconds (10-9 seconds) per function call. This lets us see that an empty loop takes 250 picoseconds = 0.25 nanoseconds per iteration = 1 clock cycle at 4GHz. The time is the same for this loop with an xor in the middle, or with an add in the middle:
mov rcx,0 ; loop counter mov rax,3 start: xor rax,7 ; add rax,2 add rcx,1 cmp rcx,1000 jl start ret
But if we do both the xor and
add, the loop takes about twice as long, because we can't finish
both operations in the same clock cycle:
mov rcx,0 ; loop counter mov rax,3 start: xor rax,7 add rax,2 add rcx,1 cmp rcx,1000 jl start ret
Something very strange happens if
we replace the "xor rax,7" with "xor rdx,7": the loop runs
fast again, in about one clock cycle! Because the xor and
add are happening on different values, the CPU can now run both
instructions at the same time. This is called superscalar
execution, and CPUs started doing that about 20 years ago.
Modern CPUs like the Intel
Skylake can run up to 8 operations in a single clock cycle: the
scheduler has 8 execution ports.
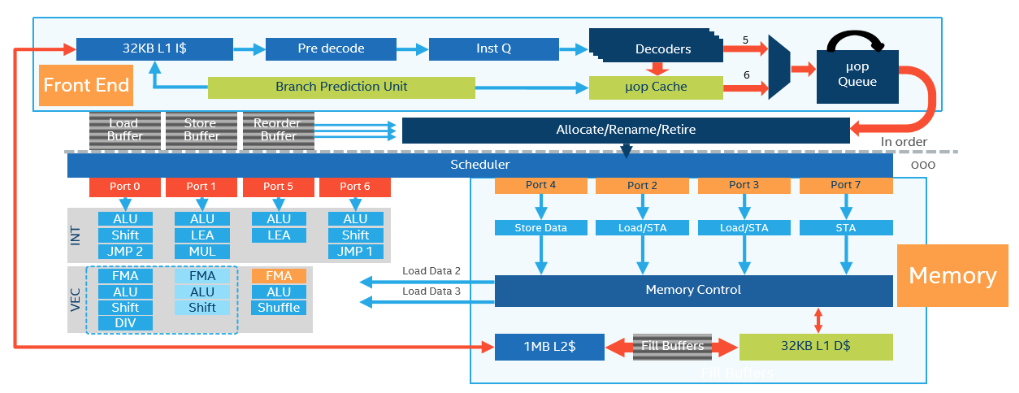
Because the CPU is superscalar,
you can do adds, compare and even memory loads at the same time:
this only takes 1 clock cycle per loop.
mov rcx,0 ; loop counter i mov rax,0 mov rdi,0 start: mov rax,QWORD[arr+8*rcx] ; load arr[i] add rcx,1 ; i++ cmp rcx,1000 jl start ret section .data arr: times 1000 dq 0
However, the CPU can only do all
this stuff in parallel if there are no dependencies
between the instructions. If we modify the code above so the
array index depends on the previous load, the code gets 5x slower
despite doing the exact same operations!
mov rcx,0 ; loop counter i mov rax,0 mov rdi,0 start: mov rax,QWORD[arr+8*rax] ; idx = arr[idx] add rcx,1 ; i++ cmp rcx,1000 jl start ret section .data arr: times 1000 dq 0
There are definitely times that
you can exploit this low-level instruction parallelism to speed up
code, even C++ code:
/*
Split factorial into even and odd product lists,
to increase instruction-level parallelism.
Skylake speedup: 4.3ns for obvious sequential code:
long prod=1;
for (long v=1;v<=12;v++) {
prod*=v;
}
return prod;
3.1ns for this code:
*/
long prodE=1, prodO=1;
for (long v=1;v<=12;v+=2) {
prodO*=v;
prodE*=(v+1);
}
return prodE*prodO;