Pipelining, Dependencies, and Register Renaming
CS 641 Lecture, Dr. Lawlor
Back in the 1980's, microprocessors took many clock cycles per
instruction, usually at least four clock cycles. They even
printed up tables of clock cycle counts
for various instructions and modes, to help you optimize your
code. This ancient situation still exists with many embedded
processors, like the PIC microcontroller. But this began to
change with the Intel 486, which used "pipelining" to cut the number of clock cycles per instruction (CPI).
The idea behind pipelining is for the CPU to schedule its various components the
same way a sane human would use a washer and dryer. For the sake of
argument, assume you've got:
- Five loads of laundry A B C D E
- They all need to be washed, dried, and folded
- Load E's already clean, and just needs to be dried and folded.
- Each load takes an hour to wash, dry, or fold
So the steps needed are as follows:
Wash A
Dry A
Fold A
Wash B
Dry B
...
Fold D
// don't need to wash E
Dry E
Fold E
Here's how a 286 would execute this program:
Hour
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
Washer
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
|
|
|
Dryer
|
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
E
|
|
Fold
|
|
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
E
|
It's an all-day job, which is clearly stupid, because only one thing is happening at once.
The sensible thing is to make a "pipeline", like an assembly line,
where you start washing load B as soon as you move load A over to the
dryer. So here's how a 486 would do the same work:
Hour
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
Washer
|
A
|
B
|
C
|
D
|
|
|
|
Dryer
|
|
A
|
B
|
C
|
D
|
E
|
|
Fold
|
|
|
A
|
B
|
C
|
D
|
E
|
That is, you start washing load D at the same time as you start folding
load B. This way, everything's busy, which speeds up the overall
program substantially--about a factor of two in this case.
Notice how long it takes to dry C--it really takes an hour, but imagine
you didn't need to do that (e.g., load C is waterproof rain gear). You can't start drying D, since
it's still in the washer. You could start folding C immediately,
but you're busy folding B. So if you leave out "dry C", the
overall process is the *same speed*. This means "dry C" is basically
free--zero clock cycles!
Back in the 1990's, I thought zero-clock instructions were really profound, in a zen kind of way.
Pipeline Stalls and Flushes
In a real CPU, the stages "A", "B", "C", "D", and "E" might be "fetch
instruction from memory", "decode instruction", "read registers needed
for computation", "compute values on registers" (execute phase), and finally "write
result back to register file" (instruction completion or "retirement").
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 R2 E2 W2 (instruction 2)
F3 D3 R3 E3 W3 (instruction 3)
F4 D4 R4 E4 W4 (instruction 4)
F5 D5 R5 E5 W5 (instruction 5)
-> time ->
But consider what happens when you execute a slow instruction like
divide--subsequent instructions might use the divided
value. The CPU hence can't execute these instructions until their
data is ready, and so the CPU must detect these dependencies (also
called "pipeline interlocks") and insert waste "stall cycles" or
("pipeline bubbles") to wait for the needed data. Pipeline stalls
can still cost
performance today--see below for software tricks on minimising
dependencies!
F1 D1 R1 E1 W1 (normal instruction)
F2 D2 R2 E2 E2 E2 E2 E2 E2 W2 (divide: 6 clock cycles)
F3 D3 R3 stall ........ E3 W3 (three stalled-out instructions)
F4 D4 stall ........ R4 E4 W4
F5 stall ........ D5 R5 E5 W5
F6 D6 R6 E6 W6 (continuing normally)
-> time ->
Smarter CPUs will only stall instructions that are waiting on that
data, rather than stopping everything in progress like I've shown above.
Here's a MIPS example that takes an extra clock cycle due to the load
into register 4 immediately being used by the next instruction, the add:
li $3, 5
lw $4, ($25)
add $2, $4, $3
jr $31
nop
(Try this in NetRun now!)
It's even worse with branch instructions--rather than just waiting,
subsequent instructions, even though they're fetched and ready to go,
might never have happened.
So these instructions need to be "flushed" from the pipeline; and
again, it's the CPU's control unit that needs to detect the situation
and do the flushing (anybody starting to smell some complexity here?).
F1 D1 R1 E1 W1 (normal instructions)
F2 D2 R2 E2 Branch!
F3 D3 R3 flush (flushed instructions-that-never-were)
F4 D4 flush
F5 flush
F9 ... (starting over at the branch target)
-> time ->
MIPS branches are pretty good, in that they only take one additional
clock cycle, and you can even specify the instruction to insert during
that clock cycle, called the "branch delay slot" instruction.
li $4, 6
li $3, 5
beq $3,$3,end_of_world
add $2, $3, $4 # Always gets executed (branch delay slot)
# Stuff in here gets jumped over
nop
nop
nop
end_of_world:
jr $31
nop
(Try this in NetRun now!)
Pipelining with Operand Forwarding
Because it might take a few clock cycles to write and then read from
the register file, and it's very common that an instruction needs the
value computed by the immediately preceeding instruction, often real
pipelined CPUs bypass the register file, and pass values directly from the execute stage of one instruction into the execute stage of the next:
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 R2 E2 W2 (instruction 2)
-> time ->
Here E2 needs the result coming out of E1, so you can put in a special
"forwarding" circuit to take it there. Note that if you don't do
forwarding, you would need to insert two
stall cycles to wait for the write and read from the register file:
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 stall R2 E2 W2 (instruction 2)
-> time ->
As usual, the CPU control unit must detect the dependency, decide to
use operand forwarding, and light up the appropriate CPU hardware to
make it happen.
MIPS is a
backronym for "Machine (without) Interlocking Pipeline Stages", because
the designers were really happy with themselves for building in operand
forwarding. It does work, since we can measure that there are no
stalls in this code, despite the back-to-back dependent "add"
instructions:
li $4, 6
add $3, $4, $4
add $2, $3, $4
jr $31
nop
(Try this in NetRun now!)
Architecture-Level Pipelining Differences
Just staring at some diagrams can tell you some of the differences
brought by pipelining. Here's the Intel 8008, a non-pipelined CPU:
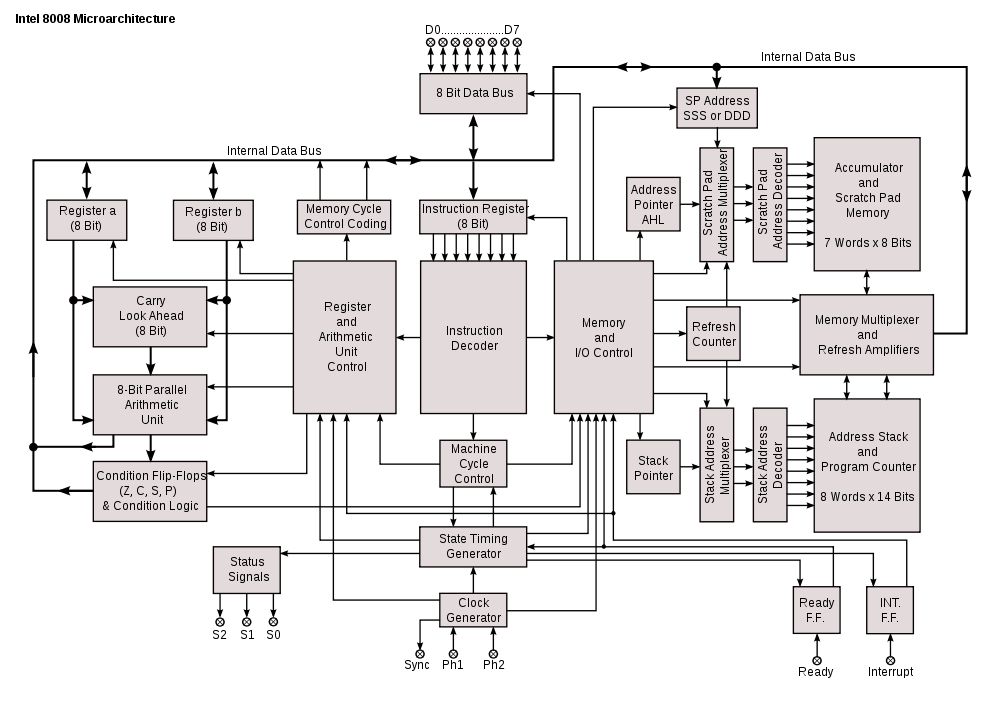
Note that there's just one bus running around the entire CPU, so
there's no possible way that multiple operations could happen at once.
Compare this with the Intel 386, a pipelined CPU:

Note that now there are many separate busses, which allow instruction fetch to happen simultaniously with execution.
It's really interesting to watch the evolution of modern microarchitectures:
- The Intel 8008, from 1972, has
a single shared internal bus used for everything: instruction fetch,
execution, memory accesses. This means it takes many clock cycles
per instruction, to interleave access to the bus.
- The Intel 386, from the 1980's, added
pipelining. The big difference is you now have many separate
busses across the machine, and need to fetch instructions in big blocks
(otherwise fetch interferes with execution memory access).
- The Intel Pentium from early 1990 added superscalar execution, so now there are multiple arithmetic units and a dependency-checking control unit.
- A recent CPU like the Intel Core2
from 2000's has renamed registers and a reorder buffer, as described
below. This is about as far as you can take performance without
changing the software.
- Since about 2005 we've had several separate processor cores per chip, which requires multicore software.
- Future CPU/GPU hybrids, like AMD's 2011 "APU A8", might combine several CPU cores with a serious graphics processor, to tackle both sequential and parallel programs.
Superscalar history
So the 1980's roll on. Machines get deeper pipelines and better
forwarding, until the machines usually initiate a new instruction every
clock cycle. Eventually, even one cycle per instruction (CPI) is not fast
enough. Sadly, one cycle per instruction is the theoretical limit
of pipelining--it's the upper bound everybody's trying to reach by
avoiding pipeline stalls, hazards, and flushes.
So as the 1990's arrived, designers began adding "wide" superscalar
execution, where multiple instructions start every clock
cycle. Nowadays, the metric is "instructions per cycle"
(IPC), which can be substantially more than one. (Similarly, at
some point travel went from gallons per mile to miles per gallon, which
is good!)
To get multiple instructions running at once, you need different
"execution units", so more arithmetic can execute at the same
time. For
example, 1994's PowerPC 601 could issue one integer, one floating-point, and one load/store instruction every clock cycle.
You can see superscalar effects in the instruction timings of any
modern CPU--many instructions simply cost no time at all. For
example, each these assembly programs take the exact same number of
nanoseconds on my Pentium 4:
ret
(Try this in NetRun now!) -> Takes 4.4ns
mov eax,8
ret
(Try this in NetRun now!) -> Takes 4.4ns
mov ecx,7
mov eax,8
ret
(Try this in NetRun now!) -> Takes 4.4ns
mov ecx,7
mov eax,ecx
ret
(Try this in NetRun now!) -> Takes 4.4ns
mov ecx,7
add eax,ecx
ret
(Try this in NetRun now!) -> Takes 4.4ns
mov ecx,7
imul eax,ecx
ret
(Try this in NetRun now!) -> Takes 4.4ns
add ecx,7
imul eax,ecx
ret
(Try this in NetRun now!) -> Takes 4.4ns
Yet this one is actually slower by two clock cycles:
mov ecx,2
mov eax,3
mov edx,4
ret
(Try this in NetRun now!)
The limiting factor for this particular instruction sequence seems to
just be the number of instructions--the Pentium 4's control unit can't
handle three writes per clock cycle.
You can avoid the substantial call/return overhead and see a little more timing detail using a tight loop like this one:
mov ecx,1000
start:
add eax,1
dec ecx
jne start
ret
(Try this in NetRun now!)
This takes about two clocks to go around each time. You can
even add one more "add" instructions without changing the loop time
(ah, superscalar!). Because the Pentium 4 uses both rising and
trailing edges of the clock, a 2.8GHz Pentium 4 (like the main NetRun
machine) can take half-integer multiples of the clock period,
0.357ns. So your timings are 0.357ns for one clock, 0.536ns for
1.5 clocks (like the loop above without the "add"), 0.714ns for 2.0
clocks (like the loop above), 0.893ns for 2.5 clocks, etc.
Superscalar Software
Here's the obvious way to compute the factorial of 12:
int i, fact=1;
for (i=1;i<=12;i++) {
fact*=i;
}
return fact;
(Try this in NetRun now!)
Here's a modified version where we separately compute even and odd factorials, then multiply them at the end:
int i, factO=1, factE=1;
for (i=1;i<=12;i+=2) {
factO*=i;
factE*=i+1;
}
return factO*factE;
(Try this in NetRun now!)
This modification makes the code "superscalar
friendly", with more exposed parallelism, so it's possible to execute the loop's multiply instructions
simultaniously. Note that this isn't simply a loop unrolling,
which gives a net loss of performance, it's a higher-level
transformation to expose parallelism in the problem.
Hardware
|
Obvious
|
Superscalar
|
Savings
|
Discussion
|
Intel 486, 50MHz,
1991
|
5000ns
|
5400ns
|
-10%
|
Classic non-pipelined CPU: many
clocks/instruction. The superscalar transform just makes the code
slower, because the hardware isn't superscalar.
|
Intel Pentium III,
1133MHz,
2002
|
59.6ns
|
50.1ns
|
+16%
|
Pipelined CPU: the integer
unit is fully pipelined, so we get one instruction per clock
cycle. The P3 is also weakly superscalar, but the benefit is small.
|
Intel
Pentium 4,
2.8Ghz,
2005
|
22.6ns
|
15.0ns
|
+33%
|
Virtually all of the improvement here is due to the P4's much higher clock rate.
|
Intel Q6600, 2.4GHz,
2008
|
16.7ns
|
9.4ns |
+43%
|
Lower clock rate, but fewer pipeline stages leads to better overall performance.
|
Intel Sandy Bridge i5-2400 3.1Ghz
2011
|
11.8ns
|
5.3ns
|
+55%
|
Higher clock rate and better tuned superscalar execution.
Superscalar transform gives a substantial benefit--with everything else
getting faster, the remaining dependencies become more and more
important.
|
Data Dependencies & Register Renaming
The biggest limit to superscalar execution, overall, is data dependencies: RAW, WAR, and WAW, also called "hazards." (Read it!)
- RAR (read after read) is not a dependency, since reads can happen in any order.
- WAW (write after write) is where I write a value after you write
it. The machine just has to make sure the correct value ends up
in the register, which is my value.
- WAR (write after read) is where I write a value after you read
it. The machine just has to make sure you get your value before I
destroy it.
- RAW
(read after write) is the hard one: I read a value after you write it.
This means I need your value, so I really have to wait for you.
You can eliminate the "fake" dependencies WAW and WAR using register renaming (also called Tomasulo's Algorithm):
a typical implementation is to hand out a new renamed register for
every write operation.
Modern CPUs rename the architectural registers (like eax through edi)
out to a huge set of *hundreds* of possible physical registers.
Also, because most values are passed directly arithmetic-to-arithmetic
(with register bypass), today a "register" is basically just an
identifier that the arithmetic units use to communicate.
There are several interesting transformations you can use to expose and reduce dependencies, such as Software Pipelining.
A naive application of these is unlikely to provide much benefit, since
the compiler and CPU can do naive transformations already; but often
you can exploit features of the algorithm to improve performance.
Plus, CPU designers has recently been shedding their most complex
features in favor of higher parallelism, so the machines of the future
may look like the machines of the past!
{kind=link}
{kind=link}
{kind=link}
{kind=link}