Pipelining
Memory is a bottleneck in High-Speed computers. Memory cycles are much slower than processor cycles. There are a few common ways of dealing with this problem in order to speed up overall processing time. One way is by storing the most frequently used memory blocks in the faster memory levels, and the slower levels will keep the memory that isn't requested as often. Another common way to relieve the bottleneck is by using parallelism.
Pipelines are a method of parallel processing at the bottleneck to help improve performance in computers. By devoting the extra hardware to install a pipeline, the increased global performance will typically outweigh the cost and improve overall efficiency. Pipelines have become a very popular way of increasing performance by means of implementing parallell hardware.
When pipelines were first being introduced hardware costs were very expensive. Since pipelines require a healthy chunk of extra hardware, computers with pipelines were the "supercomputers" of the time. In the 1980's, hardware costs were continuing to reduce, and pipelines were creating for more and more computers until they eventually became a very popular feature.
As we get into the pros and cons of pipelines, its important to look at how they work. The main idea of a pipeline is very similar to an assembly line. A new product can be started before the one before it has finished. In computers, this translates to a program (or portion of one) being started while another one is still being executed. This diagram shows what a pipeline looks like:
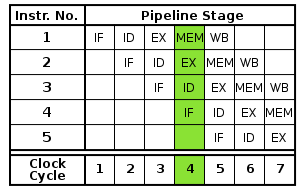
Picture is courtesy of the Wikipedia page for "Instruction pipeline."
As you can see from the picture, after the lag time to finish the first program, a program will finish every time step, helping to reduce the execution time through the bottleneck. The pipeline doesn't speed up the execution of an individual task, in fact usually it slows it down, but it increases the overall throughput of the number of tasks, relieving the bottleneck and increasing the efficiency of the processing time.
Most pipelines follow a similar structure to the following steps:
1. Instruction Fetch (IF): Obtain a copy of the instruction from memory
2. Instruction Decode (ID): Examine the instruction and prepare to initialize the control signals required to execute the instruction in subsequent steps
3. Address Generation: Compute the effective address of the operands
4. Operand Fetch : For READ operations, obtain the operand from central memory
5. Instruction Execute : Execute the instruction in the processor
6. Operand Store: for WRITE operations, return the resulting data to central memory
7. Update Program Counter: Generate the address of the next instruction
Note that pipeline is obviously limited by its slowest operation. If a Fetch takes 4 cycles for a decoders 1, then the decode will sit idly while waiting for the next Fetch. By implementing delays in the pipeline, this can provide for slow memories.
Some variants of pipelines will perform other operations during the same step as decode shown above, because the time to decode is often negligible. For example the MIPS pipeline performs a read on registers and decoding simultaneously.
Pipeline "hazards" refer to situations where the next instruction in a pipeline cannot execute in the following clock cycle. There are several situations where this problem can happen, which limit the effectiveness of pipelines.
Structural hazards refer to problems with the hardware. An example of this problem is a pipeline with multiple fetch instructions to hardware with only a single memory. If two different fetch operations are trying to simultaneously draw from the same memory, this can lead to a structural hazard.
Data hazards are another common hazard of pipelines. These refer to when a step must wait for another to complete before executing. Typically this happens when an instruction is dependent on one that is earlier in the pipeline. Example is when an add is executed but not written till later on, and another arithmetic function requires the result to be written before execution. This problem obviously will cause delays in the execution time and overall efficiency of the pipeline.
A quick case study is to look at the Pentium 4. This processor implemented a 20 stage pipeline, and some variations went even deeper.
The advantage of a deep pipeline is that the clock frequencies are much higher. This allows instructions to be executed much quicker by splitting them up. However, this size of pipeline leads to other problems which often offset the speed increase and maximum possible throughput of the pipeline. The overall potential for processing speeds is much higher with deep pipelines such as those found in the Pentium 4 than those with more shallow pipelines.
One of the biggest problems with a deep pipeline is that errors will typically take much longer to recover. More clock cycles are spent without performing useful instructions and the inevitable faulty load of an instruction is a much more costly problem than with shorter pipelines.
A picture of a 20 stage pipeline as used in the Pentium 4:

This image is courtesy of the Wikipedia page for "Pipeline (computing)."
As you can see this pipeline is much deeper than the shallow one shown above, and although has a high potential for speed also is prone to pipeline hazards.