
The vector processor goes one step beyond this and rather than just pipelining the instruction, they pipeline the data as well! Instead of the instruction saying ''Add This Integer and That Integer'', they are told to add all the integers in this set of values. By not having to fetch and decode multiple instructions, there is a substantial speed up associated with this. Also, by passing the start of an array of numbers, the processor knows that the total amount of addresses it will have to access will be between index i to [i-(n-1)] allowing it to grab all of these values concurrently, also leading to a speed up in execution. To outline the clear difference between these styles of execution, below is psuedocode for a scalar processor and a vector processor:
Scalar Version Run Loop 10 Times: Fetch the Next Instruction Decode Instruction Fetch Number A Fetch Number B Add A, B C = Result End Loop
Vector Version Fetch the Instruction Fetch 10 Numbers Fetch 10 Other Numbers Add Them All Place The Results Here
It was for this reason that for scientific applications, that require operations to be applied to lots of data as quickly as possible, that this form of CPU was really welcomed. There is a serious trade-off that comes with having hardware wanting to work on large amounts of data however, it always wants to work on large amounts of data! In fact, vector processors are only at their best when they are working on large amounts of data, and trivial problems often are much slower on vector processors than they would be on their scalar ''cousins''. As superscalar processors started taking off, vector processor usage and design made a hefty decline, and have more or less remained dormant for years following... waiting for their time to rise again!


The Cell Processor is a marvel of modern architecture, which has been equated to ''having a team of processors all working together on one chip to handle large computational workloads''.
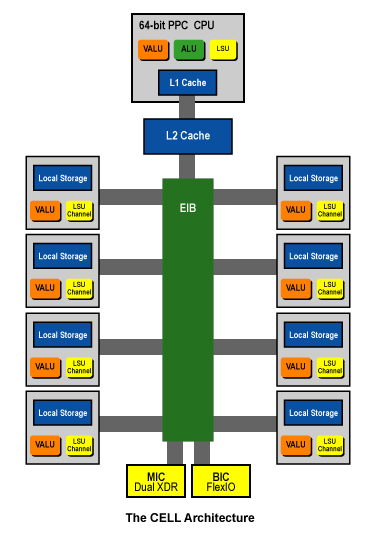
To understand how the Cell Processor works, we must delve into a portion of the research that Adam Prax will present to the class. There is a main processor on the Cell called the ''Power Processing Element'' which is a 3.2 Ghz PowerPC processor which by itself would be capable of running a modern computer framework (e.g. XBox360 uses a tri-core variation of this PPC core) , but instead this processor has the job of controlling the other processors on this chip. The PPE has the computational workload passed to it, and assesses the work that needs to be accomplished. It checks to see what the many smaller processors are currently processing and decides how best to divide the work to make most efficient use of the other processors. These processors are called ''Synergistic Processing Elements'', also referred to as ''SIMD Processing Elements'', because ''synergy is a dumb word''.
These SPEs are tiny single instruction multiple data (SIMD) 128-bit vector processors that are capable of performing a single instruction across a LOT of data! On each Cell Processor there is a total of eight SPEs that can be running parallel to one another allowing for many jobs to be run quickly.
The Cell Processor also tries to alleviate the latency between requesting a memory address from main memory (RAM) and when that memory is actually received by giving each of its SPEs its own memory! Each SPE has 256 KB of local SRAM which allows for operations to be performed very rapidly on data in this memory, which is controlled and filled by the PPE. A small side note, the PPE can also allocate this local memory to itself or any of the other SPEs if it deems such an operation necessary, which is still faster than sending the information out to main memory.
Reading from technical sources, they make mention of a change in the way instructions are done in the SPEs. IBM has actually eliminated the instruction window and the normal control logic that is associated with the instruction window.
An Aside: The instruction window on a normal CPU is a buffer between the CPU's front end (fetch, decode) and the execution of the instructions. The clearest explanation I found for this buffer came from ARS Technica, ''Instructions collect up in these buffers, just like water collects in a pool or reservoir, before being drained away by the processor's execution core. Because the instruction pool represents a small segment of the code stream, which the processor can examine for dependencies and reorder for optimal execution, this pool can also be said to function as a window on the code stream.''
ARS Technica: Instruction Window
Below is a set of images from this same site which allows for a person to see the difference between the flow of instructions in the common CPU and the Cell's SPEs:


There are a number of areas of use for the Cell Processor right now. It is used by the PlayStation 3 to ''handle the large computational workload needed to run next-generation video games'' and software. A modified (and improved) Cell Processor is also being used in the IBM BladeCenter QS-22 which is used by supercomputers for ''extreme performance'' on compute-intensive tasks such as scientific research, image and graphics rendering, and financial analytics. In fact, the most powerful supercomputer in the world, RoadRunner in New Mexico, uses these QS-22s, and has a peak performance of approximately 1.5 PetaFLOPS!
How Stuff Works: Cell Processor
Top 500 Supercomputers: June 2009
The EIB allows for the PPE to send instructions and data to the individual SPEs, and connects the many processors to each others local memory as well as the shared 512 KB L2 Cache. Below is the structure of the Cell Processor with the EIB in green running down the center:
More ARS Technica Coverage on the Cell Processor
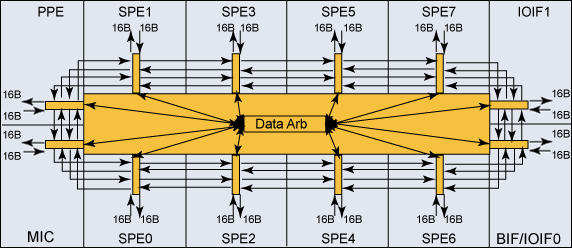
Attached to the EIB is the PPE, the memory controller (MIC), the eight SPEs, and two I/O interfaces for a grand total of 12 units. The EIB also has what is known as an arbitration unit which has the function of acting as a set of traffic lights, determining when to give the green light to allow for data to flow across the EIB. Without the arbitration unit, the many units attached to the EIB would have no concept of when to send data or receive it.
The EIB is a circular ring of four 16 byte wide single direction channels which rotate in opposite directions with its neighbor, considered a pair. When the arbitration unit permits, there can be a total of three concurrent transactions on the same ring. Also, because the EIB runs at half the system's clock rate, this means that each of these transactions can be sending 16 Bytes every 2 clock cycles. Working out the math, this means that at maximum ''concurrency'', the EIB can perform (12 Transactions * 16 Bytes)/2 Clock cycles per transfer. Thus, 192 Bytes per 2 clock cycles or 96 Bytes per clock cycle! Scaling this up to the clock cycle of the PPE, which is 3.2 GHz, this means that for each channel, the transfer rate is approximately 25.6 GB/s. That is very fast data transfer rates between elements connected to this bus. IBM often publishes that the total amount of bandwidth on this bus is ''greater than 300 GB/s''! While this estimate is high, the actual values that have been documented going across the EIB are not far off. At peak performance, the EIB is capable of doing 204.8 GB/s which is still a lot of data transferred.
IBM Senior Engineer David Krolak, the lead designer of the EIB in the Cell Processor puts the concept of the EIB in a clever metaphorical way, ''If you think of eight-car trains running around this track, as long as the trains aren't running into each other, they can coexist on the same track.'' Amongst the interview with David Krolak are images of how the EIB communicates with the different units and the arbitration unit. I have included one from this interesting discussion on the IBM website:
The EIB connects to the Memory Interface Controller (MIC), which is actually connected to the external main memory and allows for data that is flowing along the EIB to be directly written to main memory. This is known as Direct Memory Access (DMA), and allows for certain pieces of hardware to access main memory directly without having to bog down the CPU with requests to retrieve or place something into memory. This allows for the data that is finished to be placed into main memory without having to return to the PPE, and the PPE will realize that the SPE has finished processing with the next check it performs to see how much work the SPEs are doing. This DMA can come at a cost in most CPUs as Cache Coherency problems can arise. This is when a value from main memory is loaded into the cache, which allows for any subsequent operations on that data to be very fast, but make all changes to the data local to the cache. If another device requests that same data in main memory, and the new value of the data has not been flushed from the cache, you will have an old value of the data, and two completely different values will arise. This problem is solved by having the MIC be the ''bouncer'' for data exchanges, it verifies that data that has been loaded to one of the local memory slots of the SPEs or the L2 cache is used if an operation requests a memory location it has already loaded into one of these areas. Thus, the overhead that the main processor would normally have to do to pull from memory is now controlled by a different piece of hardware, but still makes sure that data is flushed to main memory regularly when it is not being used, or has been updated and finished being processed on.
Additional Information from IBM: Including MIC and EIB
That concludes my presentation on the Cell Processor and how the EIB connects the many devices on the tiny chip together. I hope you found this information interesting! I have left you my digital footprints (URLs) to allow you to do your own private research if anything is unclear or you wish to know more.
Thank you for your attention!