Multi-core Systems
CS 441 Project 1
By Christopher Start
Multiple processor setups have been in existence for quite some time. They have been around to accomplish tasks as servers, super (cluster) computing, and other embedded systems. For the purposes of this presentation, multicore will refer to multiple cores on a single die or package.
Brief History
First multicore processor (2 cores on 1 die) was the POWER4 that implemented a 64-bit PowerPC architecture in 2001 (by IBM), also had implementations of two of these cores in 1 package to equal the first quad-core processor.
Wikipedia's Entry on the POWER4 Processor < http://en.wikipedia.org/wiki/POWER4 >
Single core processor development hit a thermal and power limit with the Pentium 4 era. At which point, multiple cores began to appear (Pentium D – though technically
two single core dies placed next to each other; in terms of performance, it was very close to putting two Pentium 4s in the processor slot). This was succeeded by a true multicore processor on July 27th, 2006 (Core2 architecture introduced).
*Tom’s Hardware Review of the Pentium D <http://www.tomshardware.com/reviews/pentium-d,1006.html>
*Intel's Official Pentium D Product Page <http://www.intel.com/products/desktop/processors/pentiumd/pentiumd-overview.htm>
The main focus and idea became that if you can do more things at once, the less time it will all take (and thus overall performance is improved). This idea of spreading the work load out has become a large focus for development today (think: threading).
Advantages:
If you manage to spread the work load out (user is doing multiple applications, single application is well threaded, etc), you can get closer to n times speed up for the n number of cores you have. This can give you something roughly similar to having a dual core CPU clocked at 2.0GHz running similarly to a single core 4.0GHz processor (though realistically, never quite the same).
Disadvantages:
Need an Operating System to spread the multiple threads/processes across the multiple cores available (and in some intelligent way).
To get advantages in individual programs, they need to be optimized to spread the work load out into multiple threads (written in parallel).
Thermal dissipation issues – Need to get rid of that extra heat from packing multiple cores so tightly together. Some systems (like the CELL processor) include temperature sensors.
Power management – Power requirements can grow very quickly by adding more cores, and this can become extremely inefficient if the workload doesn’t use them. Most multicore systems now include some method of power control to drop the voltage being supplied to cores that are not being used.
Cache Coherency – the problem that since each core has some level of private cache (atleast Level 1, if not also Level 2), the data may not be up-to-date. There are two primary methods of resolving this issue, a snooping protocol and a directory-based protocol. Snarfing is a third method that involves watching both the address and data, when the memory is changed, it updates its own copy of the data.
A snooping protocol only works with a bus-based system (like Intel’s current design) which is not scalable (it has a limit of roughly 32 cores before the bus becomes completely saturated with all the calls since they are broadcast to all cores). It uses a number of states to determine it needs to update the entries in the cache (by flagging its own copy as invalid if it sees data being written to a location it currently has loaded) and if it has control for writing to that entry.
The directory-based protocol works on a network and is thus, scalable. A directory is used to hold information about what sections of memory have been loaded into caches and what sections are used by just one core. This directory knows when a section needs to be updated or invalidated. Directory messages are point to point, and thus use less bandwidth (as opposed to broadcasting like snooping). Directories do tend to be slower and have longer latencies.
Of note, Intel’s Core2 architecture by letting the cores query each other’s L1 cache. And since the L2 cache is shared, there doesn’t need to be a coherence protocol in place for that level of cache. In contrast, AMD’s Athlon 64 X2 has to monitor cache coherence in both its L1 and L2 caches. They try to speed things up by using their HyperTransport connection.
 |
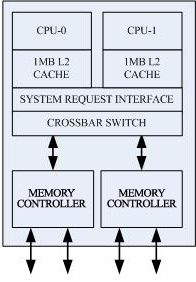 |
| From Bryan Schauer's page who references L. Peng et al, "Memory Performance and Scalability of Intel's and AMD's Dual-Core Processors: A Case Study", IEEE, 2007 |
|
Homogeneous vs Heterogeneous Cores
There is also currently a debate going on whether it is better or more efficient to have the cores all be the same (same frequency, cache sizes, abilities) or to have heterogeneous cores like the CELL processor which has a dedicated Power Processing Element. Homogeneous cores are easier to manufacture as they are identical and the instruction is the same. Heterogeneous cores have specialized instruction sets and may be faster for those specific/specialized tasks, this could also spread the heat generation, power requirements, and increase efficiency.
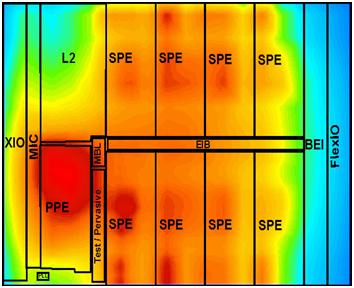 |
From Bryan Schauer's page who references D. Pham et al, "The Design and Implementation of a First-Generation CELL Processor", ISSCC |
Additional References:
- Multicore Processors: A Necessity. by Bryan Schauer. http://www.csa.com/discoveryguides/multicore/review.php?SID=vv9jorp03o4fk44thoq94mdcd1
- Wikipedia’s Multi-core: http://en.wikipedia.org/wiki/Multicore_processor
- Wikipedia’s Cache Coherency: http://en.wikipedia.org/wiki/Cache_coherency
- Wikipedia’s Athlon 64 X2: http://en.wikipedia.org/wiki/Athlon_64_X2
- AMD's Multi-core processor Introduction: http://multicore.amd.com/Resources/33211A_Multi-Core_WP_en.pdf