
Introduction
Graphics processors have changed the last 10 years.
Nowadays, they are able to do more than just render some vertex on screen. We
will see first the difference between CPU and GPU. After, we will see how new
graphics cards are architectured. Finally, we will see how to use graphics cards like a co-processor.
CPU vs. GPU
1.
Power
The power required for computer games and for
3d-modeling in general increase drastically since few years. This piece of
silicon which was before optional is now one of the major part of the system.
At the beginning, graphics cards were just here to help CPU on specific task,
now they take more and more functionality.
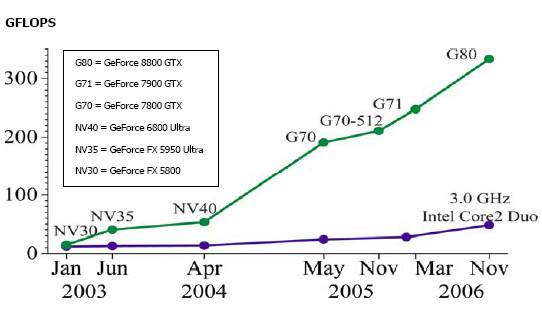
This diagram shows the confrontation between CPU
and GPU on floating point operations.
2.
Cost
The main market to
graphic card reseller is video game player. He is the only market which can buy
enough video card and which is ready to pay the same price a video card and a CPU.
It’s why the cost
of GPU stays reasonably low.
|
GPU |
$514 |
|
|
GPU |
$420 |
|
|
GPU |
$199 |
|
|
CPU |
$316 |
|
|
CPU |
$224 |
The price is also a
crucial element in the war. Why use SMP if my old graphic card could do better?
3.
Aim
A CPU is expected to process a task as
fast as possible whereas a GPU must be capable of processing a maximum of tasks
on a large scale of data. The priority for the two is not the same, their
respective architectures show that point.
GPU increase the number of
processing units and the CPU develop control and expend his cache.
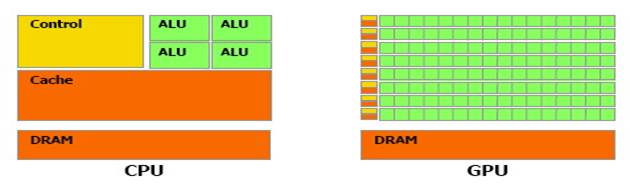
As we can see, GPU are highly parallel!
4.
Memory bandwidth
Memories are often a
limited factor for a system. CPU try to remove this limitation by expending the
size of cache memory.
|
|
Type |
Speed |
|
Nvidia |
GDR3 |
83.2 Go/s |
|
ATI |
GDR4 |
128.0 Go/s |
|
INTEL Core 2 duo |
DDR2 |
6,4 Go/s |
This trick
doesn’t work if you work on a large amount of data. GPUs are faster
memory certainly because new generation comes out every 6 months.
5.
Float precision
Accuracy is something
really important for scientific problem.
|
|
Floating Point Precision |
|
ATI GPU’s |
64 |
|
Nvidia GPU’s |
64 (32 on 8800) |
|
Processor |
128 (double on 64bits processors) |
The future generation
of GPU will exceed the accuracy of the CPU.
GPU Architecture
1.
Stream processor
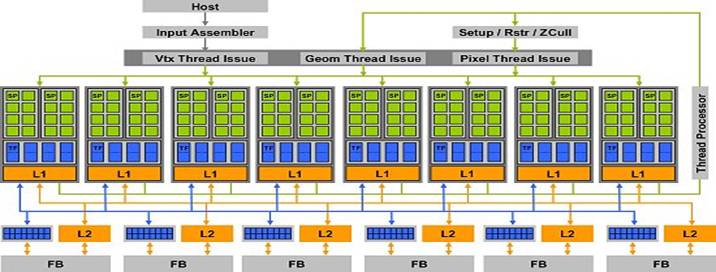
The 8800 is composed by
128 stream processor turning at the frequency of 1350 MHz each. A processor is able to
do an MAD and MUL calculation
per
clock cycle. They need 4
cycles for specials instructions like EXP, LOG, RCP, RSQ, SIN, COS managed by
an extra unit.
Ati
for the 2900XT chose another architecture. Instead using SIMD like Nvidia, they
use MIMD 5-way. That means
five instructions are dependant from each other. Each group of 5 processors has
a special unit able to handle special instructions. A Radeon HD 2900 can handle
320 simple operations or 256 simple + 64 special ones. The frequency is 742 only MHz.
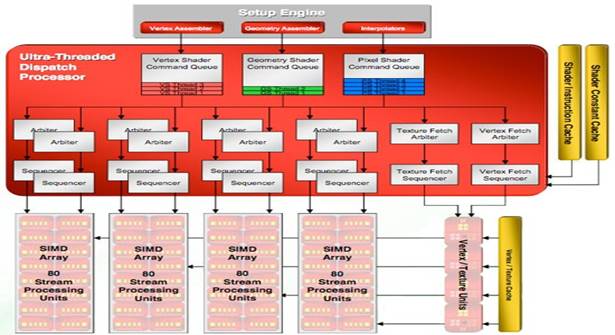
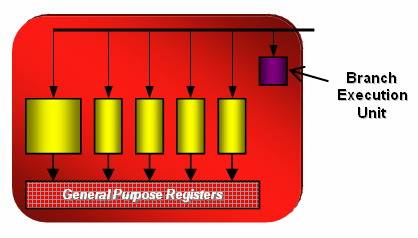
These
two architectures show the new tendency of constructor. Multiply the unit to do
simpler calculus. Parallelize data at the maximum.
2.
Memory organization
GPU are capable of reading and writing anywhere
in local memory (on the graphic card) or elsewhere (other parts of the system).
These memories, however, are not cached, and the cost of the latency of
reading/writing cycles for the GeForce 8800 oscillates between 200 and 300
cycles! This latency can be masked by the extremely long pipeline, if they
don’t wait for a reading instruction.
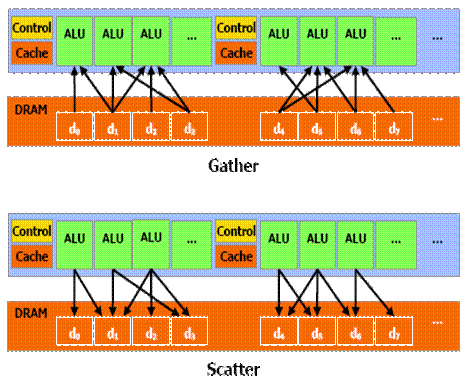
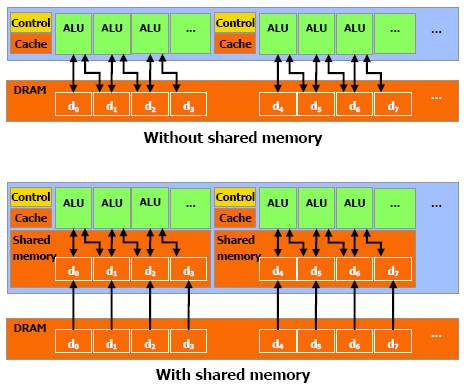
To avoid as much as possible access to global memory,
each multiprocessor has a small dedicated memory (16KB). They are called shared
memory because memory can be used by other processors in the same block.
GPGPU
1.
Definition
General-purpose computing on graphics
processing units
(GPGPU, also referred to as GPGP and to a lesser extent GP²) is a recent
trend focused on using GPUs to perform computations rather than the CPU. The
addition of programmable stages and higher precision arithmetic to the
rendering pipelines allowed software developers using GPUs for non graphics
related applications. By exploiting GPU's extremely parallel architecture using
stream processing approaches many real-time computing problems can be sped up
considerably.
2.
Implementations
a. How running
code on GPU?
Vertex and pixel shader
were added to graphics pipeline to produce more realistic effect. The
specifications given by Microsoft increase the flexibility and capacity with
each revision.
This is why you
can nowadays run code on GPU!
b. Brook
Brook for GPUs is a compiler and runtime
implementation of the Brook stream program language for modern graphics
hardware. Brook is an extension
of standard ANSI C and is designed to incorporate the ideas of data parallel
computing and arithmetic intensity. It is a cross platform language able to run
on ATI and Nvidia, Linux and windows, DirextX and Opengl.
The main goal of this language is to make the
programming easier. Try to not use Graphic functions and simply the common
operation.
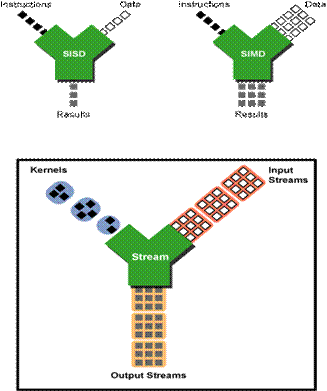
Stream processing is a new paradigm to maximize
the efficiency of parallel computing. It can be decompose in two parts:
Stream: It’s a collection of objects
which can be operated in parallel and which require the same computation.
Kernel: It’s a function applied on the entire
stream, looks like a “for each” loop.
c. CUDA, CTM
Nvidia and ATI approach
differ on GPGPU.
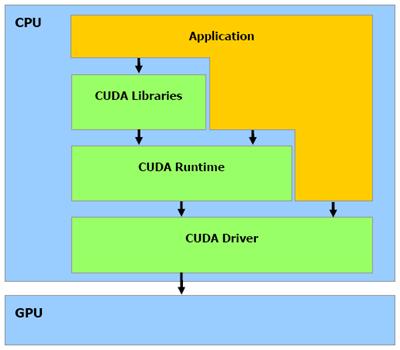
Nvidia provide a fully
SDK for a high layer programming. Concretely you write a C-like code and the
Nvidia library take care of all the communication with the graphics card. They
give libraries, comparator and specific driver.
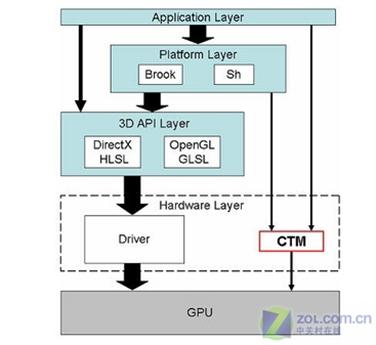
Ati develops a low
level interface call “close to metal”. Ati lets the developer
community create the entire library and the high layer application. Actually, a
middleware exists in Brook to use CTM. Maybe one day, one middleware will be
creating between CUDA and CTM.
Both provide back end
to run the code faster than graphics libraries on stream processors.
3.
Applications
We have
already identified certain standards that we can carry to the GPU:
·
Linear algebra libraries like BLAS, ATLAS or
LAPACK...
·
Basic arithmetic
·
Trigonometry
·
Transcendental functions
·
Operations, identities and inversion of matrices
·
Resolution
of equation systems of unknown N
·
Calculation by finished elements
·
Convolutions
·
Generation of random numbers
·
Linear algebra
·
VaR computing
·
Monte Carlo
Every application which
need parallel computing can be a good application.
4.
Future
a. Larabee
Intel wants to introduce into SSE4 some High Level Shading Language. That
concretely means Intel plans to develop a GPU to do massive parallel computing.

The
interesting thing is they want to keep the X86 instructions set! Larabee could be exploited like GPU or
like a Co-processor.
b. AMD's Fusion
AMD plans to integrate GPU in the same die of
CPU to reduce latency between the components.
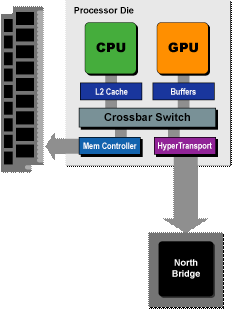
We can now easily imagine a multi-core configuration
where GPU will be either GPU or Co-processor.
Conclusion
We
have to keep in mind that GPUs evolve really fast. They have optimized to
handle parallel data instead of CPU which are powerful to handle parallel
tasks. Programming a GPU will become easier with time and the domain of
application is wide.
Bibliographies
GPGPU
http://en.wikipedia.org/wiki/GPGPU
http://download.nvidia.com/developer/GPU_Gems_2/GPU_Gems2_ch29.pdf
http://graphics.stanford.edu/~mhouston/public_talks/R520-mhouston.pdf
http://www.behardware.com/articles/659-4/nvidia-cuda-preview.html
http://www.behardware.com/articles/678-1/nvidia-cuda-practical-uses.html
http://graphics.stanford.edu/projects/brookgpu/
GPU Architecture
http://www.behardware.com/articles/671-2/ati-radeon-hd-2900-xt.html
http://www.behardware.com/articles/644-1/nvidia-geforce-8800-gtx-8800-gts.html
http://anandtech.com/video/showdoc.aspx?i=2870&p=5
Other
http://en.wikipedia.org/wiki/FLOPS
http://arstechnica.com/news.ars/post/20061119-8250.html
Glossary
http://www.guru3d.com/article/article/430/