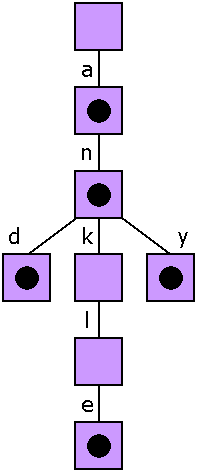
- In the context of Hash Tables, what is “open addressing”?
- What is a “probe sequence”?
- Name and describe three kinds of probe sequences.
- Give a disadvantage of open addressing over other techniques.
- What problems occur when a Hash Table gets too full?
- What is the “load factor” of a Hash Table?
- What should be done when a Hash Table gets too full?
- What problems does the procedure from the previous part create?
- What advantages do Hash Tables have over search trees, as a Table implementation?
- What disadvantages do Hash Tables have (list three disadvantages)?
- “Use Hash Tables intelligently,” says your instructor. Explain.
double arr[20];
for (int i = 0; i < 20; ++i)
arr[i] = i + 7.1;
cout << arr[3] << endl;- Change this code so that instead of an array, it uses one of the STL Table implementations. Make as few changes as possible. You may assume that the required header files have already been included.
- Changing the above code in this way is probably a bad idea. Why?
Why is there no const version of this operator?const std::map<int, int> m = mymap; // No problem cout << m[0] << endl; // COMPILER ERROR! m is const
- Key. The key type.
- Data. The data type.
- HashFcn. The hash function.
- EqualKey. A comparison for determining whether two keys are equal.
- Alloc. The allocator, for internal memory management. For the purposes of this exercise, you can ignore Alloc.
- Based on the above information, we can conclude that SGI’s std::hash_map does not implement buckets as search trees. How do we know this?
- What should the worst-case performance of the insert, delete, and retrieve operations be for this container? (By the way, the three operations are actually called “insert”, “erase”, and “find”.)
to set the item’s value. The same is true for a std::deque and std::list. However, this is not the case for the STL Table implementations (std::set, std::map, etc.). Why not?*iter = value;
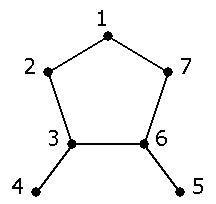
- Give the ordering in which vertices would be visited in a DFS of this graph. Start at vertex 1. Visit low-numbered vertices first, where possible.
- Same as above, but do a BFS.
- Explain how to implement a DFS.
- Explain how to implement a BFS.
- ... a Hash Table?
- ... a search tree?
- What does it mean to keep an “index” to a data structure? (Note: I am speaking of a separate data structure used to index another, NOT the concept of the index of an item in an array.)
- Under what circumstances is it a good idea to keep an index to a data structure?
a, an, and, ankle, any
- Name the two solutions.
- Discuss trade-offs between the two solutions.
- Is there a situation in which we might not use one of the two “best” solutions? Explain.
- Sorting a sequence.
- Searching for an item in a sequence.
- Implementing a Table.